ハイブリッド k3s · 第1回
ハイブリッド k3s #1: クラウドと自宅を一つのクラスタに(最初のセットアップ)
この記事の原文は Zenn で公開しています。
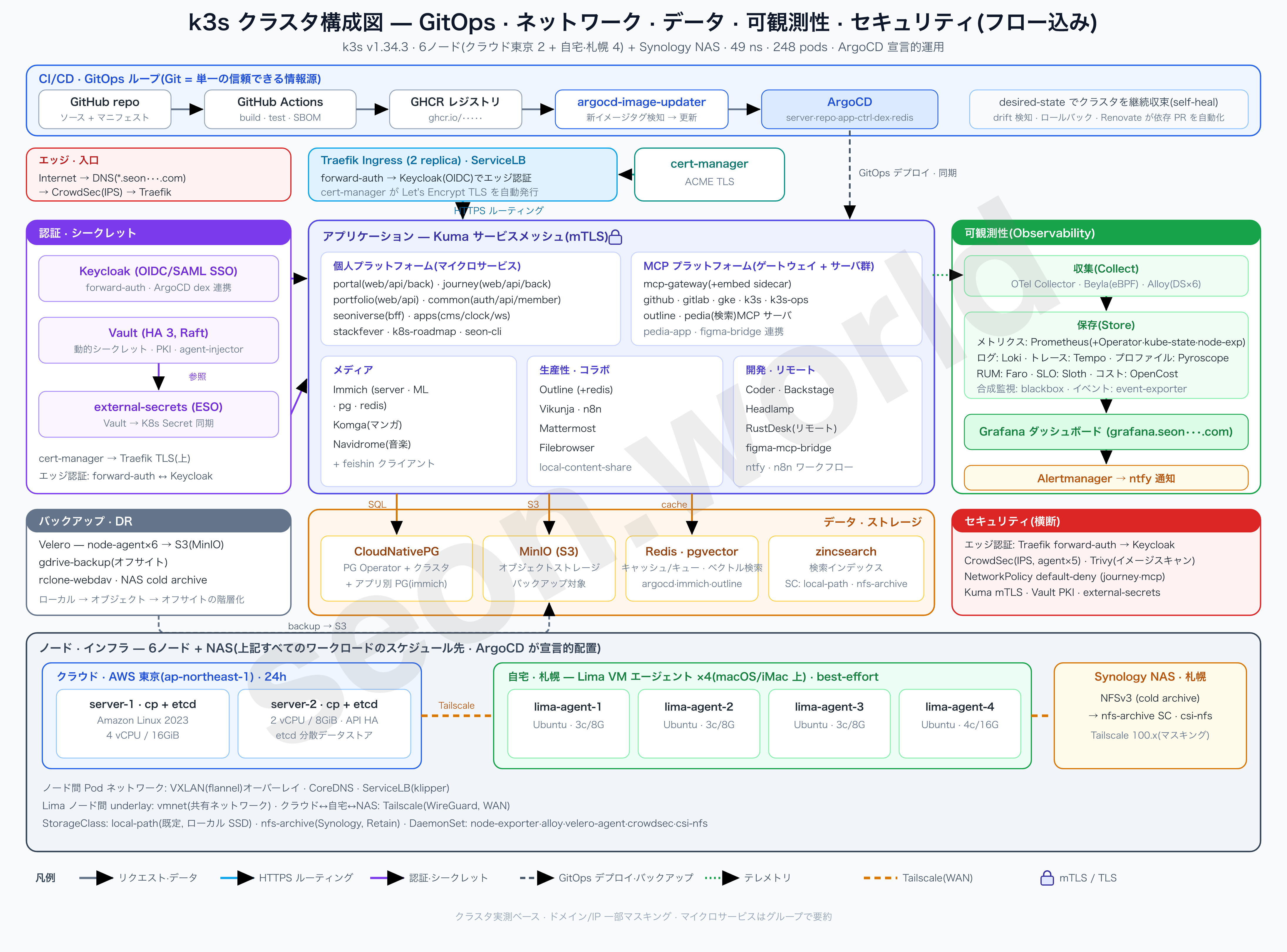
0. このシリーズについて
このシリーズは、上の構成図のように 今まさに運用しているホームラボをどう作ったのかを、一つずつ記録していく記事です。
「できるだろうか?」という疑問から始めた私のトイプロジェクトは、満足のいく性能で、壊しては組み直しながら、仕事で溜まったストレスを解いてくれる本物のオモチャになってしまいました。
リソースが潤沢なクラスタではありませんが、Kubernetes の環境を十分に味わうことができ、これからもっと広げてみたいことが次々と湧いてくる良い環境になりました。
- ノード 6台 — クラウド(AWS 東京)Lightsail server 2台(コントロールプレーン+etcd) + 自宅(札幌)iMac の Lima VM agent 4台
- 合計 19 vCPU / 61 GiB、ネームスペース 49個、Pod 248個(稼働 150)
- デプロイは ArgoCD、認証は Keycloak OIDC、その上に CloudNativePG・Vault・CrowdSec・Prometheus/Grafana などが稼働中
簡単ではありませんでしたが、かといって諦めるほど難しくもなかったので、これまで構築しながら学んだこと、そして残しておきたいことを一つずつ整理していこうと思います。
最初の話はその土台 — クラウドのコントロールプレーン2台からどう始めたか、についての内容です。
1. 背景
立派な設計図が先にあったわけではありません。出発点はごく平凡でした。
本業で Kubernetes を扱っていると、もっと深く確かめたいことが出てきます。ドキュメントを読むのと、自分の手でクラスタを壊して直してみるのとは違いますよね。会社でも触れる環境はありますが限られていて、下手に触ると面倒な事態を招くので限界がありました。
「自分の思うままに動かせるクラスタ」が必要だった。
ちょうど自宅には、10年以上前の 64GB RAM の iMac がほぼ遊んでいました。今でも十分な性能を発揮しますが、HDD が付いていて遅く、OS のサポートも終わってしまい、MacBook Pro M4 に席を譲って休んでいる状態です。さらにクラウド側には、すでに個人サービスを動かしていた小さな Lightsail インスタンス2台があり、サービスが増えるにつれて少しずつリソースが厳しくなってきたところでした。
「遊んでいる自宅マシンのリソースと、すでに料金を払っているクラウドを、別々にせず一つにまとめて使えたら?」
学習欲とリソースの圧迫は、一つの考えに収束しました — クラウドと自宅を一つのクラスタにまとめる。 この記事はその最初のひと掘り、クラウド側の土台を築く話です。
2. なぜ k3s だったか — 限られたリソースでの選択
まず Kubernetes(以下 k8s)環境を用意しましょう。
しかし私が持っているクラウド環境のリソースでは、標準の k8s は重すぎました。気持ちとしては数千ノードがぶら下がったマルチクラスタで自由に暴れたかったのですが、現実は月 $150 ほどの小さな AWS Lightsail インスタンスと、引退間近の10年超えの iMac 1台でした。
「どの Kubernetes で行くか」から選ぶ必要がありました。調べた結果は以下のとおりです。
| 選択肢 | 性格 | 今回の状況では |
|---|---|---|
| マネージド(EKS/GKE/AKS) | クラウドがコントロールプレーンを代行運用 | コントロールプレーン料金 + ノード費用 → 低コスト・遊休機材の活用と衝突、除外 |
| 正統 Kubernetes(kubeadm) | アップストリームを自前で組み立て | 最も王道だが重く手間がかかる → 低スペック・小規模には負担、除外 |
| k3s (Rancher/SUSE) | 単一バイナリの軽量ディストリ | 軽量ディストリ — 最終候補 |
| k0s · MicroK8s | 似た系統の軽量ディストリ | 同じく軽量ディストリ — 最終候補 |
| minikube · kind | ローカル開発・テスト用 | 永続マルチノード運用向けではない → 除外 |
こうして絞ると、候補は k3s · k0s · MicroK8s の3つの軽量ディストリになりました。3つをさらに掘り下げると:
| 項目 | k3s (選択) | k0s | MicroK8s |
|---|---|---|---|
| 製作元 | Rancher/SUSE | Mirantis | Canonical |
| パッケージング | 単一バイナリ | 単一バイナリ | snap パッケージ(snapd 依存) |
| 既定のデータストア | SQLite(kine)、HA は embedded etcd | etcd 標準(kine で他 DB も) | dqlite(分散 SQLite, Raft) |
| HA 方式 | 複数 server 時に etcd へ切替 | 標準で提供 | 3ノード〜自動 HA |
| コントロールプレーン | server がワークロードも兼ねる | 内部コンポーネントを別プロセスに、コントロールプレーン分離 | ノード単位 |
| 既定の CNI | flannel(軽量、ポリシー制限あり) | kube-router/calico | calico(HA 版) |
| バンドル傾向 | 必須コンポーネント同梱(Traefik・ServiceLB・local-path…) | ミニマル、既定コンポーネントを差し替えやすい | アドオンを microk8s enable で有効化 |
なぜ k3s だったか。
3つとも CNCF 準拠の軽量ディストリですが、性格が違います。
k0s はコントロールプレーンをワークロードと分離していて綺麗ですが、その分だけ同梱物が少なく、自分で組み込むものが多くなります。
MicroK8s は microk8s enable の一行でアドオンを有効化できる手軽さがある反面、snap に縛られ、dqlite が書き込みの多いクラスタで CPU・合意の不安定事例が報告されています。(GitHub Issue #3227)
一方 k3s は、単一バイナリに必須コンポーネントが同梱されていて初回セットアップが最も速く、複数 server で embedded etcd へ移行する流れが、今回のような「クラウド+自宅 HA」と自然に噛み合います。低スペック・ARM サポートに、ドキュメント・コミュニティの厚みも加わり、学習と低コスト運用を同時に狙う今回の目的には k3s が最もよく合いました。(比較出典: Palark · Portainer · nOps)
k3s はその Kubernetes を 100% 互換(CNCF 認証)を保ったまま、単一バイナリ(100MB 未満) にまとめたディストリです。要件も事実上、現代的なカーネル + cgroup だけなので、低スペックでも無理がありません。(What is K3s)
軽い理由を3つだけ挙げます。
- 単一バイナリ・単一プロセス。 通常の Kubernetes なら別々に立つ
kube-apiserver・kube-scheduler・kube-controller-manager・kubelet・kube-proxyを一つのk3sプロセスに包み、コンテナランタイム containerd も内蔵する。(Architecture) - データストアが柔軟だ。 単一 server なら既定で SQLite、複数 server なら embedded etcd が自動選択される(外部 MySQL/Postgres も可)。(Datastore)
- 必須コンポーネント同梱。 flannel(CNI)・CoreDNS・Traefik(Ingress)・ServiceLB・local-path(ストレージ)・metrics-server をインストール時に一緒に立ててくれる。自前で組み立てる分がそれだけ減る。
おまけに、k3s のノードは server(コントロールプレーン+データストア)と agent(ワークロード専用)の2種類なので、「クラウド=server、自宅=agent」のようなハイブリッド構成と相性が良かったです。この点は4章以降の図で確認できます。
3. コントロールプレーン — 3台が定石、しかし2台で挑戦
元々クラウドでは Docker Compose で個人サービスを動かしていました。小さいインスタンス1台は DB 用、大きいインスタンス1台は複数のマイクロサービスを担当する形でした。この2台を Kubernetes へ移そうとして、最初の悩みがコントロールプレーンの部分でした。
Kubernetes が安定するには コントロールプレーンの HA が基本です。
k3s の embedded etcd は過半数(クォーラム)を保たないと書き込みができず、公式 HA ガイドは server 3台以上(奇数) を推奨する。ノードが n 台ならクォーラムは (n/2)+1 となり、ノード数からクォーラムを引いた数が、耐えられる障害ノード数になります。
| server 数 | クォーラム | 耐えられる障害 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
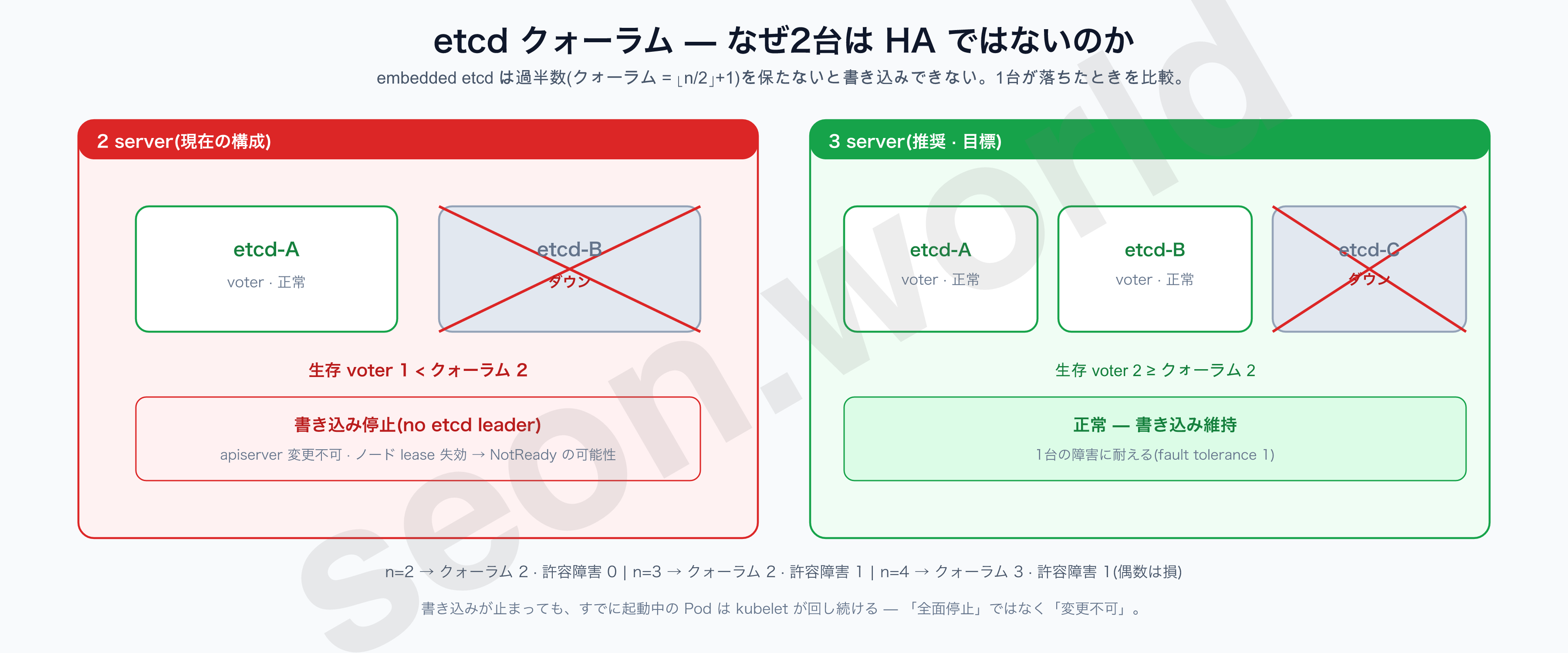
定石は 3台です。しかしインスタンスをもう1台増やすには懐事情が厳しく、そこで目標を変えました。
3台が正解だと分かっているが、ひとまず 2台でできるだけ安定的に 回してみよう。
2台を選ぶにあたり、2つのことを明確にしました。
第一に、1台に全部を寄せない。
以前、コントロールプレーンとサービスを1台のノードに全部載せて、大きく痛い目に遭いました。
Lightsail は バースト可能(burstable)CPU モデルで、プランごとに vCPU あたりのベースライン % が決まっており、負荷がその上に長く留まると貯めておいた バースト容量を消費し、0 になるとベースラインへ降格します。コントロールプレーン(apiserver・etcd)まで同じノードにあると、CPU が枯れた瞬間にクラスタ制御そのものが止まるため、負荷を分けて2台に分割しました。
| ノード | プラン | vCPU | ベースライン | 役割 |
|---|---|---|---|---|
| server-A | 8GB ($44/月) | 2 | 30% | cluster-init · control-plane+etcd+worker |
| server-B | 16GB ($84/月) | 4 | 40% | join · control-plane+etcd+worker |
記事執筆時点で使用量を見ると、両方ともベースライン以下(持続可能ゾーン)でバーストを貯めている状態です(kubectl top nodes):
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cp-8gb-init 482m 24% 4565Mi 58%
cp-16gb-join 1153m 28% 10096Mi 65%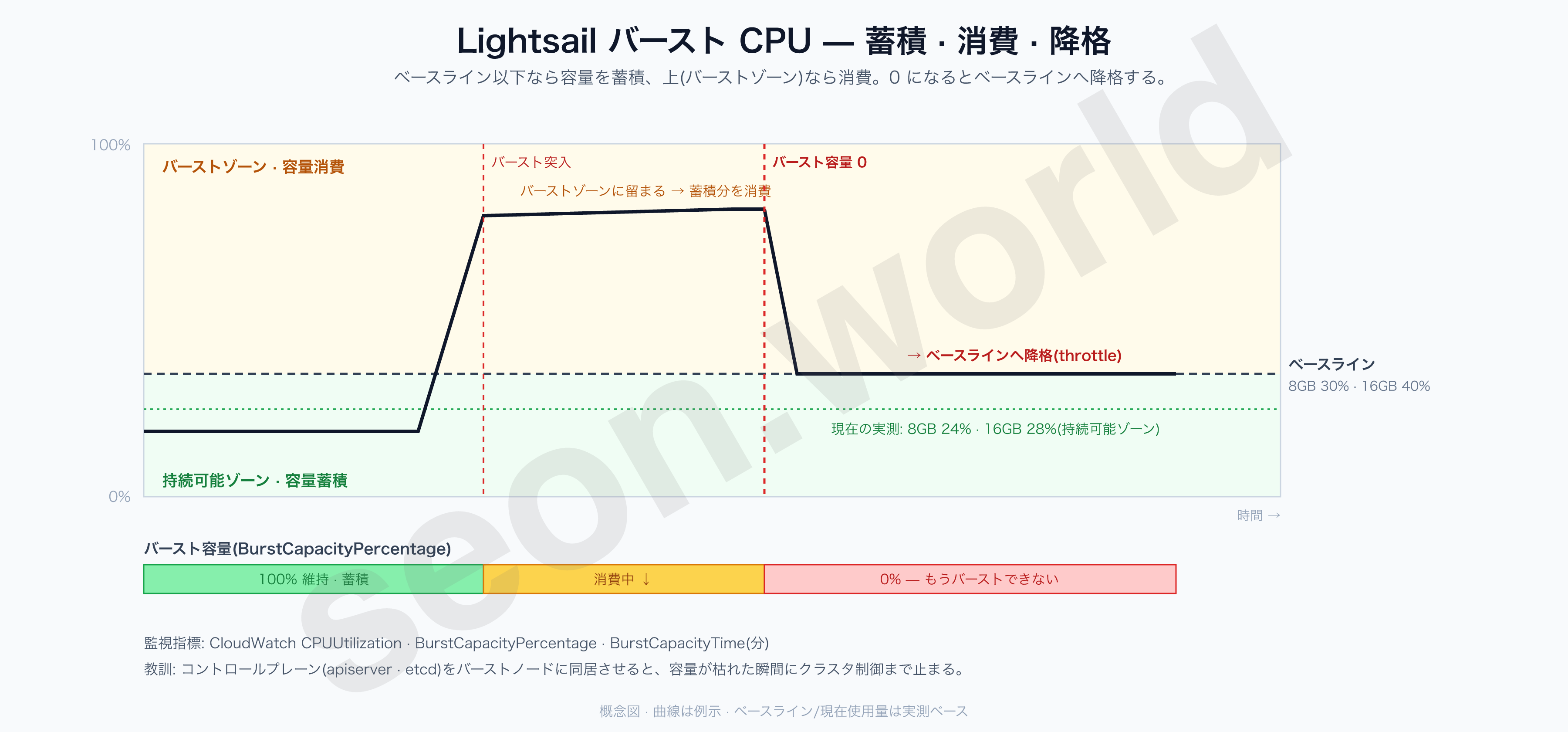
第二に、2台が HA でないことを認め、保険をかける。
上の表のとおり、2台は1台でも落ちるとクォーラムを失い書き込みが止まります(すでに起動している Pod は kubelet が回し続けるので「全面停止」ではなく「変更不可」)。そのリスクは etcd の自動スナップショットで埋めます。私たちは別途設定していないので k3s の既定値 — 0 */12 * * *(1日2回)、5個保持、/var/lib/rancher/k3s/server/db/snapshots — で回ることになります。(etcd-snapshot) ローカルにしか溜まらないので、後で NAS/オブジェクトストレージへ退避することを課題として残しました(バックアップ回)。
4. 今日の主役 — Tailscale
コントロールプレーンは東京の Lightsail に、ワーカーに使うマシンは札幌の自宅 iMac にあります。
この2つは プライベートネットワークを共有していません。
自宅マシンはルーターの裏のプライベート IP(192.168.x)なので外から直接は届かず、ポートを開けて公開しようとすると kubelet(10250)・VXLAN(8472)のようなクラスタ用ポートをインターネットに晒す羽目になり危険です。k3s がノードを一つのクラスタにまとめるには、全員が互いを 安定した一つのアドレスで呼べる必要があるのに、今の構成にはそれがありません。
そこで VPN・Mesh から方法を探すことにしました。
| 選択肢 | 性格 | 今回の状況では |
|---|---|---|
| ポート直接公開 + グローバル IP | VPN なしでそのまま公開 | kubelet・VXLAN をインターネットに晒すことに → 危険、除外 |
| raw WireGuard | 高速なカーネル VPN、手動の鍵/ピア | 速いが NAT 越え・鍵管理・アクセス制御すべて手作業 |
| OpenVPN | 伝統的なハブ型 VPN | メッシュよりハブ中心、設定が重い |
| ZeroTier | マネージドのメッシュ VPN | 十分な候補、毛色が近い |
| Tailscale | WireGuard + コーディネーション(メッシュ) | NAT 自動越え・ACL・MagicDNS・無人キー、個人無料 ← 選択 |
| Headscale | Tailscale コントロールサーバのセルフホスト | より自由だが自前運用の負担 → 後で検討 |
実際には多くの試行と悩みに時間を費やしましたが、結果的には Tailscale を選びました。WireGuard ベースのメッシュ VPN で、各マシンにデーモンを入れてログインすると、自分のアカウント専用のプライベートネットワーク(tailnet)に入り、マシンごとに 100.x 帯のアドレスが一つずつ付きます。このアドレスは、マシンが東京にあっても札幌のルーターの裏にあっても どこからでも同じ値で到達できます — NAT は Tailscale が勝手に越えてくれます。
クラウドと自宅を一つの平面に乗せる「仮想 LAN」を敷ける、ということです。(しかもマシン100台まで登録無料)
k3s はノードを登録するとき --node-ip で受け取ったアドレスをそのノードのアイデンティティ(InternalIP)として刻むので、この値を最初から Tailscale アドレスにしておけば、後で自宅ノードが合流するときも同じ 100.x 平面にそのまま乗せられます。だから k3s より先に Tailscale を 入れることに決めました。
5. Tailscale 登録 · インストール · 確認
順番は 登録 → インストール → 確認。
① 登録。 login.tailscale.com で Google・GitHub・Microsoft などの SSO アカウントでログインすると、そのアカウント専用の tailnet が自動で作られます。別途の会員登録フォームはなく、SSO がそのまま登録になります。

{kind=link}
② (サーバ用)認証キーの準備。 クラウドサーバにはブラウザがないので、管理コンソール Settings → Keys で auth key(tskey-…)を事前に発行しておきます。対話的に繋ぐなら飛ばしても構いません。

{kind=link}
③ インストール & 接続。 2台のクラウドノード(Amazon Linux 2023)それぞれで:
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up # 表示された URL で認証 (ヘッドレスなら --authkey tskey-… )
tailscale ip -4 # このノードの 100.x アドレス — 6章の --node-ip にそのまま使う④ 確認。 管理コンソール Machines(login.tailscale.com/admin/machines)に2台のノードがそれぞれ 100.x アドレス・ホスト名とともに表示されれば成功です。

{kind=link}
ノード側でも確認できます:
tailscale status # tailnet 内のマシン一覧 + 各自の 100.xこれで2台のクラウドノードが一つの tailnet で互いに 100.x で見えるようになる。では、このアドレスで k3s を立てます。(Tailscale Linux インストール)
6. k3s インストール (Tailscale アドレスで)
5章で確認した 100.x をそのまま --node-ip に入れます。
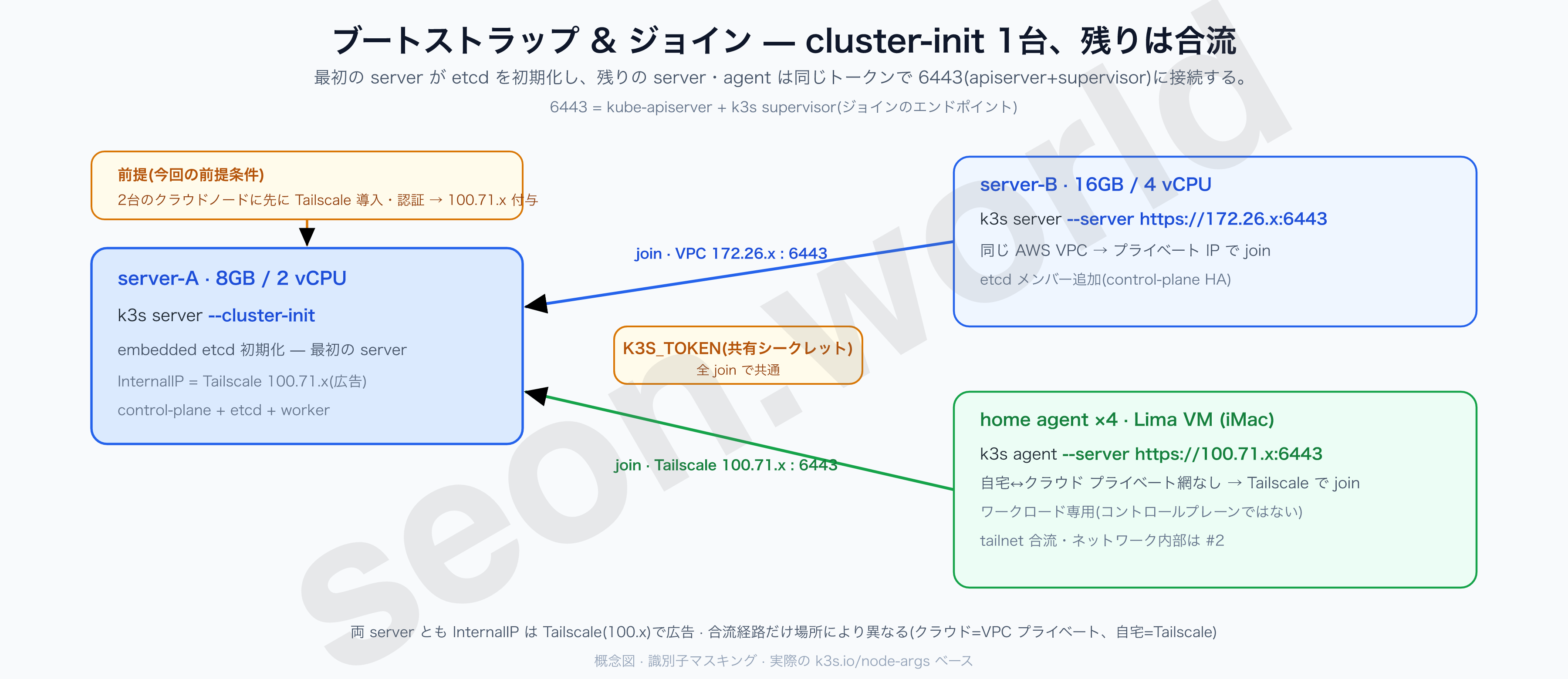
server-A (8GB):
curl -sfL https://get.k3s.io | K3S_TOKEN=<共有シークレット> INSTALL_K3S_VERSION=v1.34.3+k3s1 \
sh -s - server \
--cluster-init \
--node-ip 100.71.x.x \
--node-external-ip <グローバルA> \
--advertise-address 100.71.x.x \
--flannel-backend vxlan--cluster-init— 最初の server として embedded etcd を初期化する。(server flags)--node-ip 100.71.x.x— 5章で受け取った Tailscale アドレスを InternalIP として広告する。--node-external-ip/--advertise-address— グローバル IP(外部公開用)、apiserver の広告アドレス(Tailscale)。--flannel-backend vxlan— CNI バックエンド(既定値だが明示)。
K3S_TOKEN は、自分でパスワードを決めるように任意の値を指定してもよく、空欄にしておけば k3s が自動生成してくれます。ただし join するにはこの値を知っている必要があるので、別途保存しておくか、下記パスの値をそのまま渡しても構いません。
/var/lib/rancher/k3s/server/node-token
server-B (16GB) — 2台目の server として join。 このノードも先に tailnet に入れてから、同じトークンで繋ぐだけです:
curl -sfL https://get.k3s.io | K3S_TOKEN=<シークレット> INSTALL_K3S_VERSION=v1.34.3+k3s1 \
sh -s - server \
--server https://172.26.x.x:6443 \
--node-ip 100.99.x.x--server https://172.26.x.x:6443= server-A のアドレス(同じ VPC なのでプライベート IP)。--node-ip 100.99.x.x= このノードの Tailscale アドレス。
2台の Lightsail は 同じ AWS VPC 内なので合流自体はプライベート IP で行いましたが、クラスタに広告する InternalIP は両方とも Tailscale(100.x)です。
ファイアウォール — 外部には最小限だけ開けます。(requirements)
| ポート | 用途 | 公開 |
|---|---|---|
| 80 / 443 | Traefik Ingress | 全体 |
| 22 | SSH | 自分の IP 限定 |
| 6443 / 2379-2380 / 8472 / 10250 | apiserver·etcd·flannel·kubelet | 公開は閉じ、プライベート/Tailscale 内部のみ |
7. クラスタ構成 — 2台で完成
自宅 iMac を agent として繋ぐのは次の記事で説明します。
ここまでで Tailscale まで適用した Lightsail 2台でクラスタを構成しました。
ノードを表示すると、両方とも同じバージョン・ランタイムで Ready になっているのが確認できます。
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
…3-146(8GB) Ready control-plane,etcd 139d v1.34.3+k3s1 100.71.x.x 52.x.x.x Amazon Linux 2023.7.20250512 6.1.134-…amzn2023.x86_64 containerd://2.1.5-k3s1
…2-70(16GB) Ready control-plane,etcd 139d v1.34.3+k3s1 100.99.x.x 3.x.x.x Amazon Linux 2023.9.20251105 6.1.156-…amzn2023.x86_64 containerd://2.1.5-k3s12台のノードが etcd の投票メンバーかどうかを確認します(kubectl describe node <ノード名> の Conditions を確認):
Conditions:
Type Status Reason Message
---- ------ ------ -------
EtcdIsVoter True MemberNotLearner Node is a voting member of the etcd cluster
MemoryPressure False KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False KubeletHasSufficientPID kubelet has sufficient PID available
Ready True KubeletReady kubelet is posting ready statusk3s の既定バンドルが立っているかも確認します(kubectl get pods -n kube-system):
# kubectl get pods -n kube-system → k3s 既定バンドルのみ抜粋
coredns-7f496c8d7d-nx9jc 1/1 Running 139d # DNS
local-path-provisioner-578895bd58-mgxpm 1/1 Running 139d # ローカルストレージ(既定 SC)
metrics-server-7b9c9c4b9c-76ldg 1/1 Running 139d # メトリクス(kubectl top)
traefik-78df465dcc-66kn8 1/1 Running 9d # Ingress (server-A)
traefik-78df465dcc-gs4q7 1/1 Running 8d # Ingress (server-B) → 2台に1個ずつ = 2レプリカ
helm-install-traefik-crd-pmk4t 0/1 Completed 139d # バンドルを入れた Helm Job(完了)ここまでが、クラウドインスタンス2台を k3s クラスタとして構成する説明でした。単に k3s をセットアップしただけではなく、今後 agent として、どこに・どんな形で存在していても、k3s を構成できる環境でさえあれば参加できるよう、Tailscale の設定もしておきました。
8. 次は
AWS の Lightsail ノードはクラスタとして構成できました。そしてノードたちが参加できる準備も整いました。
結果的には各ノードあたりコマンド1行で終わることだったのですが、思ったより時間がかかった段階でした。
こうして2台で構成したクラスタに、本格的に自宅で休んでいる iMac を参加させてみます。
iMac に Lima VM をインストールし、それぞれ agent を作って同じ tailnet に合流させ、合流させた後に直面した問題も一緒に解いていく記事を書いていきます。
参考 / 出典
- k3s — What is K3s / Architecture / Datastore: https://docs.k3s.io/ · /architecture · /datastore
- k3s — HA Embedded etcd / Server flags / etcd-snapshot / Requirements: https://docs.k3s.io/datastore/ha-embedded · /cli/server · /cli/etcd-snapshot · /installation/requirements
- 軽量ディストリ比較(k3s·k0s·MicroK8s): https://palark.com/blog/small-local-kubernetes-comparison/ · https://www.portainer.io/blog/k0s-vs-k3s · https://www.nops.io/blog/k0s-vs-k3s-vs-k8s/
- Tailscale — Linux インストール: https://tailscale.com/kb/1031/install-linux
- AWS Lightsail — バースト CPU/ベースライン: https://docs.aws.amazon.com/lightsail/latest/userguide/baseline-cpu-performance.html